
PHIlter (protected health information filter) team
managers: hunter mills, lakshmi radhakrishnan
tools: python (pandas, numpy, spacy)
institute website // project repository
intro
The Bakar Computational Health Sciences Institute (BCHSI) is a division of the University of California San Francisco dedicated to applying computational tools to help solve medical problems, from helping process sound data used to image living hearts to building models to understand how genetics impact common diseases.
At UCSF, I worked on PHIlter, an open-source project dedicated to de-identifying clinical notes (text documents doctors write during patient visits to note both quantitative and qualitative observations). Through de-identifying these notes by removing personal health information (PHI, such as names, locations, dates, etc.), the data in these notes could be made more widely available for research study, all while protecting the privacy of patients.
my work
My project revolved around creating a post-processing algorithm for PHIlter’s de-identified
output. Initially, PHIlter simply marked each case of identifying information with a
standardized tag (e.g. [***NAME***] where a patient’s name was listed) in the text. This could lead to issues of privacy in cases where PHIlter has a false-negative (i.e. fails to
detect a phrase as identifying information, as would happen roughly 1 percent of the time), as
the identity of the patient would be quickly revealed.
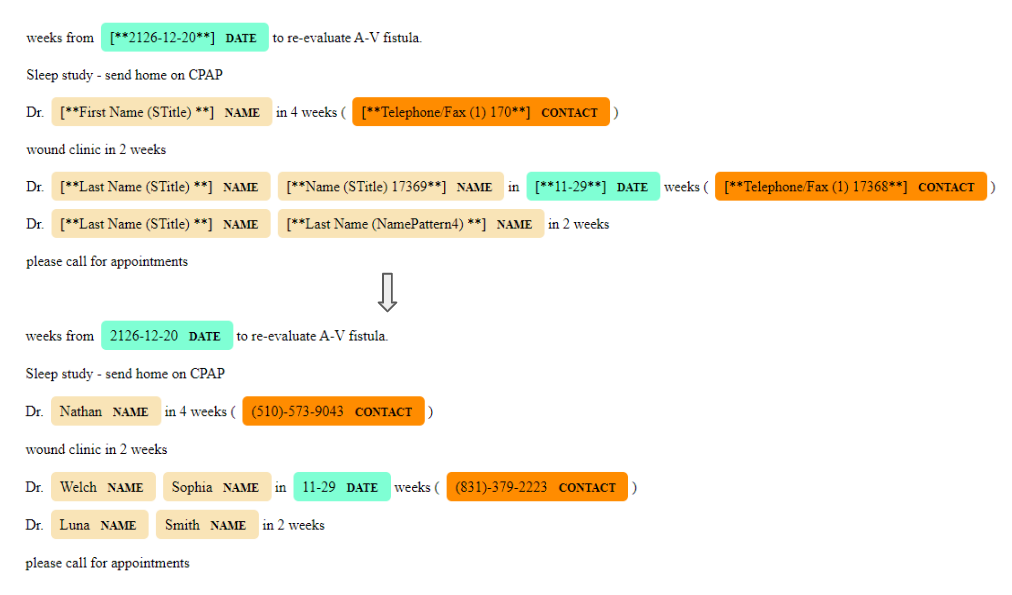
Sample PHI replacement made by my algorithm! Dates were already de-identified in a way that preserved the relative timing of events.
I was charged with writing software to replace these censoring tags with randomized data, helping to hide these false-positives “in plain sight.” In order to keep the ‘camouflage’ intact, therefore, it was important to ensure that this data matched the context of the original identifying information.
My algorithm supported a host of identifying information types, from names to dates, phone numbers, even various random locations around the Bay Area. This project not only challenged me in terms of complexity, but also in terms of scale. The program had to run over the i2b2 clinical notes test dataset, which contains nearly 2 million notes (and that was just the proof of concept!), so efficiency and simplicity were key considerations, particularly as the size of i2b2 pales in comparison to the number of clinical notes generated by the UCSF healthcare system, where PHIlter was intended to be used.
other learnings
Aside from using data libraries such as pandas and numpy on a large scale for the first time, my time at UCSF also allowed me to get a first-hand look at the forefront of computational biology research, as well as the dynamics within a large research institution such as UCSF. It was fantastic seeing how the tools I had learned about in class translated into solving real-world problems, and how a diverse group of developers, researchers, even doctors can come together to work towards a collective end goal.
Thank you also to Hunter Mills and Lakshmi Radhakrishnan, as well as the rest of the PHIlter team, whose mentorship over the summer taught me many life lessons and technical skills!